
|
|
  









 |
Batch Text Encoding Converter is an easy-to-use application that can help you convert
Encoding of multiple ansi/ utf-8/ unicode/HTML Encoding plain text
documents to and from any Encoding, either interactively or in batch mode. It
can convert Encoding of thousands of files within a few minutes minutes.
Text Encoding Converter just does plain text conversion, for example, it can
convert Encoding of text, php, xml, html files and more from
ansi to unicode.
Text Encoding Converter is not a file format converter! for example, it can not
convert
PDF to text files; from
Word to
Html files or anything else like that.
This is a terminology mistake that people new to computing sometimes make, mixing up the words "Encoding" and "format". Text Encoding Converter can convert the Encoding of XML and HTML files, however you may need to manually edit the Encoding declaration of the resulting file.
| Western European (ISO-8859-1) Central European (ISO-8859-2) Esperanto (ISO-8859-3) Baltic (old) (ISO-8859-4) Cyrillic (ISO-8859-5) Arabic (ISO-8859-6) Greek (ISO-8859-7) Hebrew (ISO-8859-8) Turkish (ISO-8859-9) Nordic (ISO-8859-10) Thai (ISO-8859-11) Baltic (ISO-8859-13) Celtic (ISO-8859-14) Western European with Euro (ISO-8859-15) Windows Thai (CP 874) Japanese SHIFT-JIS (CP932) Chinese simplified GBK (CP936) Korean EUC-KR (CP949) Chinese traditional BIG5 (CP950) |
Windows Central European (CP 1250) Windows Cyrillic (CP 1251) Windows Western European (CP 1252) Windows Greek (CP 1253) Windows Turkish (CP 1254) Windows Hebrew (CP 1255) Windows Arabic (CP 1256) Windows Baltic (CP 1257) Windows/DOS OEM (CP 437) Unicode 7 bit (UTF-7) Unicode 8 bit (UTF-8) Unicode 8 bit (UTF-8) NO BOM UTF-16BE UTF-16LE UTF-32BE UTF-32LE Japanese EUC-JP |
| HTML Encoding |
08/26/2013 Released Text Encoding Converter v3.0 build130826, fixed the error that it can't convert utf-8 HTML Encoding format files.
08/20/2013 Released Text Encoding Converter v3.0 build130820, added HTML Encoding format to source file encoding format, now you can convert special HTML Encoding unescaping text to utf-8 or native character encoding, thanks for Matt Weiss's advice.
for example < to < , < to < or → to →,
這是測試腳本 to 這是測試腳本
これは、テストページ to これは、テストページ
这是测试脚本 to 这是测试脚本
이 테스트 페이지 to 이 테스트 페이지
08/16/2013 Released Text Encoding Converter v2.0 build130816, added [-dfn:destincation file name] command line option that you can appoint the destination file name in command line, and fixed the error popuping twice save dialog.
06/30/2012 Released Text Encoding Converter v2.0 build120630, added function that the destination file has same file time as the source file, thanks for Mark Ogier's advice.
03/14/2012 Released Text Encoding Converter v2.0 build120314, fixed utf8 conversion error.
05/31/2011 Released Text Encoding Converter v1.0 build110531, updated product help information and application text information, very thanks for Peter Polash's kindly help.
08/30/2010 Released Text Encoding Converter v1.0 build100827, added command line interface, thanks for Thomas Jensen's advice.
05/25/2010 Released Text Encoding Converter v1.0 build100525, added NO BOM utf-8 file format to destination file format list. In Text Encoding Converter GUI, you only select "unicode 8 bit (utf-8) NO BOM" item from destination file format list, then do conversion, final you can get no BOM utf-8 files, thanks for Gert Van Assche's idea.
10/20/2009 Released Text Encoding Converter v1.0 build091020, fixed conversion error while selecting "convert files to same file path".
10/10/2009 released Text Encoding Converter v1.0 build091009.
| GUI for win |
Automatic check source file encoding, convert to utf-8 and preserver source file's newline format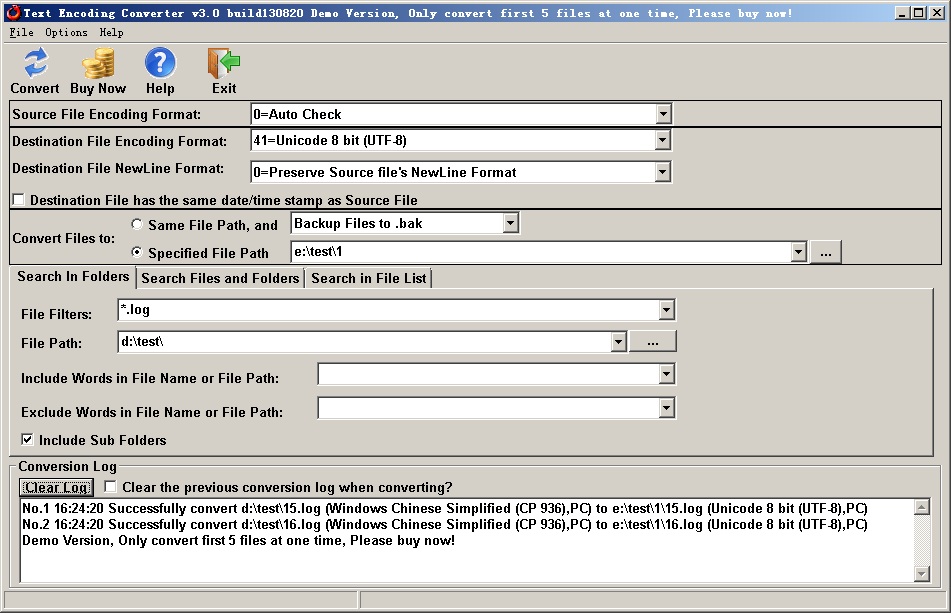 |
Don't convert the
Encoding format, only
convert newline characters to DOS (CR/LF)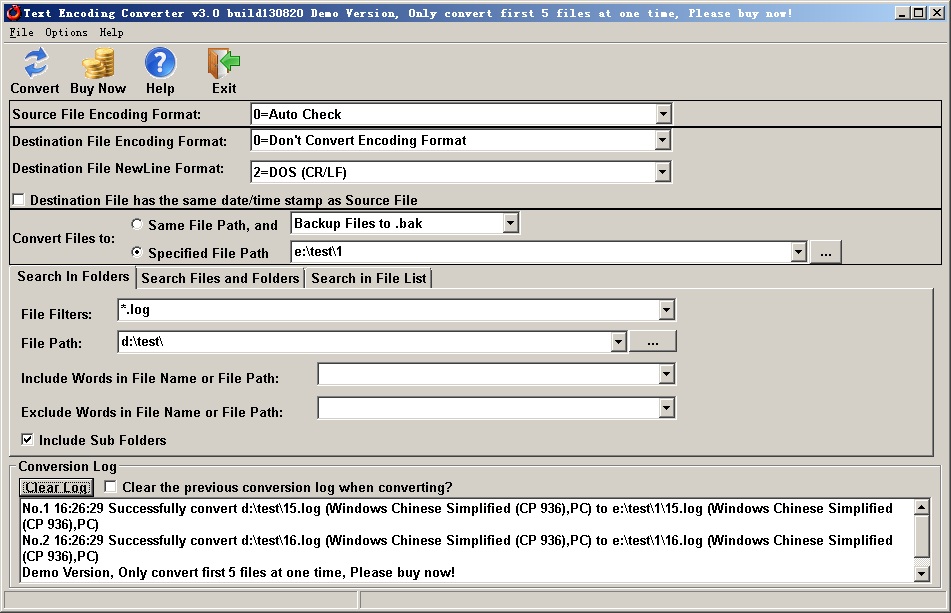 |
How can I run the program from the command line?
tec <source
file path> <-de:destination encoding code> [-dfn:destination file name] [-dp:destination file path] [-dn:destination
newline code] [-se:source encoding code] [-is] [-iw:include words] [-ew:exclude
words] [-b2b] [-b2p:bak to path] [-nb] [-sametime]
Please notice: add quotes when argument contain spaces
| source file path | The path and files to be converted. This
parameter must exist. for example, "d:\source\*.txt" (use quotes when paths contain spaces) |
| -de:destintation encoding code | Destination Encoding code. This
parameter must exist. You can get the full code list from the graphical interface , please see the following red frame. for example, -de:41, the destination Encoding is utf-8 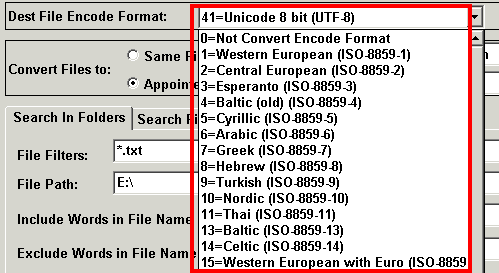 |
| -dp:destination file path | Destination file path. For example, -dp:"d:\dest files" if this parameter is ignored, the source file will be converted to the same file path, and the source file will be overwritten. (Use quotes when the destination path contains spaces.) |
| -dfn:destination file name | Destination file name, for example, -dfn:"d:\dest files\dest1.csv" |
| -dn:destination newline code | Destination newline code. You can get the full code list
from the graphical interface, please see the following red frame. For example, -dn:0, means DON'T convert the newline format. For this setting, the source file's newline formatting is preserved in the destination file, altered only as needed to satisfy the requirements of the destination Encoding code.  If this parameter is ignored, it is the same as -dn:0. |
| -se:source encoding code | Source Encoding code,. You can get the full code list in the
graphical interface, please see the following red frame. for example, -se:0, TEC will automatically determine the source file's Encoding format 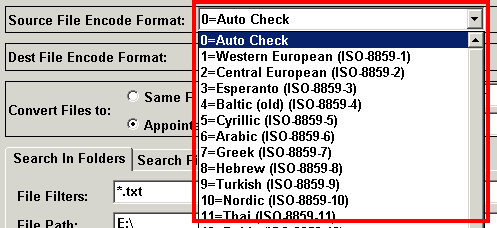 If this parameter is ignored, it is the same as -se:0, ie, auto detection of source file Encoding format |
| -is | Include sub-folders; If specified, source files contained in sub folders of the source path folder will be converted as well. |
| -iw:include words | Include words in source file name or file path. Only convert
files whose names include the specified words. Used for wild card or entire
folder source paths. for example, -iw:test;2010*.log, means convert only those source files whose files names include "test" or are of the form "2010*.log" |
| -ew:exclude words | Exclude words in source file name or file path. Only convert
files whose names do not include the specified words. Used for wild card, or
entire folder source paths. for example, -ew:.bak, source files with an extension of .bak will excluded. |
| -b2b | Backup files to .bak, used when the destination path is the same as the source |
| -b2p:"bak to path" | Backup files to specified path,. Used when the destination
path is the same as the source path. For example, -b2b:"d:\bak". Source files will be backed up to the folder "d:\bak" (Use quotes when the path contains spaces) |
| -nb | Don't backup source files |
| -sametime | The destination file has same file time stamp as the source file, so that you will not loose track of dates changed |
Command Line Example 1:
tec "c:\source file\*.php" -de:41 -b2b -is
This will convert *.php files in the "c:\source file\" folder, and its
sub-folders,to the utf-8 file
Encoding format, and it will backup the original
source files to the same folder using the .bak file extension
Command Line Example 2:
tec "c:\source file\*.php" -de:-2 -dn:1 -dp:"d:\dest file" -is -ew:.bak -sametime
This will convert *.php files in "c:\source file" and its sub-folders
to the
utf-8 no bom file Encoding format, and
convert to unix newline format, the
destination file path is the folder "d:\dest file", and it will not convert .bak
files in source file path, and the destination file has same file time stamp as the source file.
Command Line Example 3:
tec "c:\source files\source1.php" -de:41 "-dfn:c:\dest files\dest1.php"
This will convert source1.php file in the "c:\source files\" folder to dest1.php file in the "c:\dest files" folder, the destincation encoding format is the utf-8 file
Encoding format.
What's Unicode?
Unicode provides a unique number for every character, no matter what the
platform, no matter what the program, no matter what the language. There are
several Unicode encodes: the most popular is UTF-8 Encoding and UTF-16 Encoding. UTF-8
Encoding uses a
variable-length character Encoding, and all basic Latin character Encoding codes are
identical to ASCII Encoding.
I have more questions - who should I write to?
Please send your additional questions to gofunnowcom@gmail.com.
You will get the register version download url by email within 12 hours after you finish your order.
| License Type | Price | Buy From paypal.com |
| Single User License (+ 12 months Free Upgrade and 12 months Free Technical Support) Runs on any windows OS include windows server, ONE License restricts to ONE user only. |
$249( |
|
| Site License (+ 12 months Free Upgrade and 12 months Free Technical Support) Allows use of the program by members of the same organization within a single town or city. |
$1249 |
|
| Worldwide License (+ 12 months Free Upgrade and 12 months Free Technical Support) Covers all members of a single organization worldwide |
$2999 |
|
| Developer License (+ 12 months Free Upgrade and 12 months Free Technical Support) After you order the developer license, there is not any limit for the developer license, you can bundle our product to your application, then redistribute your application to anyone, any times, and anytime. |
$2999 | |
| Upgrade to the newest version from any previous version (+ 12 months Free Upgrade and 12 months Free Technical Support) | $125 |
 Download free trial, only convert first five files at one time,
run 30 times
Download free trial, only convert first five files at one time,
run 30 times